
Microsoft a révélé un outil capable de simuler la voix et la parole d’une personne lorsqu’on lui donne seulement trois secondes d’échantillon audio pour le baser.
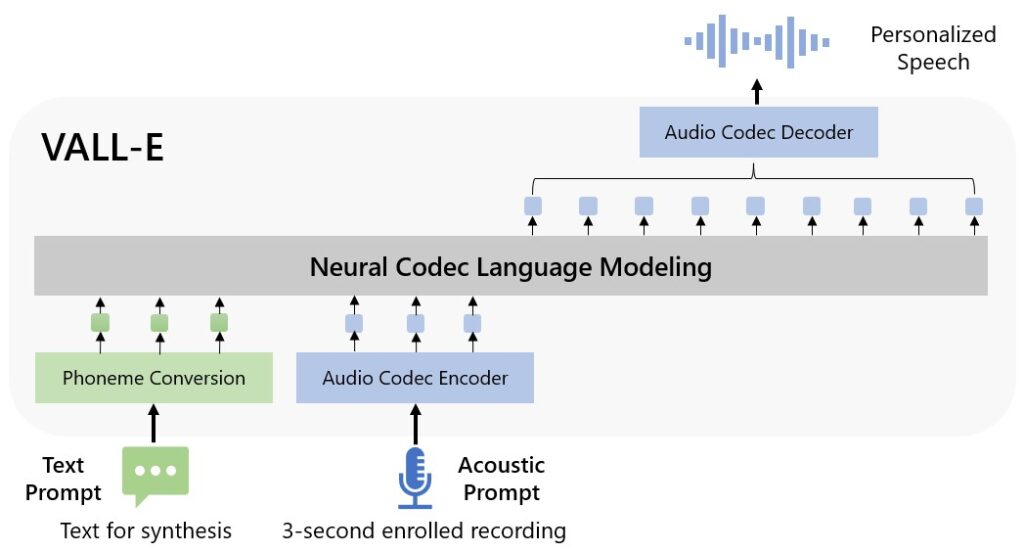
L’outil VALL-E est un modèle de langage de codec naturel, selon les recherches, et peut être utilisé pour synthétiser la parole. L’idée est d’améliorer les capacités de synthèse vocale et de la rendre un peu plus naturelle.
Dans un publier sur GitHubMicrosoft affirme que même avec un échantillon de parole très limité, la technologie est capable de maintenir l’authenticité et l’émotion dans la voix.
Que l’orateur soit en colère, amusé, dégoûté ou endormi, VALL-E peut maintenir l’émotion lorsqu’il simule la voix. Ce n’est pas encore parfait, loin de là, et semble avoir des problèmes avec certains des accents les plus forts, mais dans l’ensemble, c’est assez impressionnant pour une preuve de concept.
L’entreprise a formé l’outil à l’aide de la technologie créée par Meta, appelée LibriLight. Il a 60 000 heures de discours en anglais de 7 000 locuteurs. Meta a créé la technologie pour tenter de combler les lacunes des appels audio lorsque le signal est faible, mais Microsoft a d’autres objectifs en tête.
Comme pour tout ce qui concerne l’IA, il y aura des craintes que la technologie ne soit utilisée à mauvais escient pour donner l’impression que quelqu’un a dit quelque chose qu’il n’a pas dit. C’est quelque chose que nous avons déjà expérimenté avec les deepfakes vidéo.
Cependant, si la technologie est utilisée pour les bonnes raisons, elle pourrait aider les personnes qui ont perdu la voix à communiquer à nouveau avec les autres dans leur propre discours.
Vous ne pouvez pas encore l’essayer par vous-même, mais Microsoft a a sorti beaucoup d’échantillons (via Ars Technica) présentant la technologie.
Dans un article expliquant les essais, Microsoft déclare: «VALL-E émerge des capacités d’apprentissage en contexte et peut être utilisé pour synthétiser un discours personnalisé de haute qualité avec seulement un enregistrement inscrit de 3 secondes d’un locuteur invisible comme invite acoustique. Les résultats des expériences montrent que VALL-E surpasse de manière significative le système TTS zéro-shot de pointe en termes de naturel de la parole et de similarité des locuteurs. De plus, nous constatons que VALL-E pourrait préserver l’émotion de l’orateur et l’environnement acoustique de l’invite acoustique en synthèse.









{kind=link}